Overview
abstract
Platform: Python
First upload date: 2025-12-15
I. 들어가며
2화에서는 모델링 과정이 진행됩니다.
팀원끼리 원하는 알고리즘을 가지고 각자 모델링 해보기로 했고, 저는 ARIMA와 Tensorflow의 keras 패키지를 이용한 분류 신경망 모델을 사용하였습니다.
II. Feature Engineering
1. 파생 변수 생성
아래와 같은 변수들을 추가로 생성합니다
- 시간/날짜 변수:
year,month,dayofweek,weekofyear,is_weekend,season - 판매 채널 기반 변수:
is_marketplace,is_ownmall,is_wholesale,marketplace_ratio,ownmall_ratio,wholesale_ratio - 재무 관련 변수:
margin_rate(수익률),cost_per_unit(단위당 원가),profit_per_unit(단위당 이익). - 제품 특성 변수:
style(모델과 색상 조합),size(사이즈 버켓: small, medium, large) - 지리적 변수:
sido(광역 시/도),sido_group(수도권, 영남권 등) - 기타 변수:
acg_temp_mena,esi_mean - 시계열 특성:
lag_1,lag_7,lag_30(전일/7일전/30일전 매출),roll7_mean,roll30_mean(7일/30일 이동평균),roll7_std(7일 표준편차), lag/rolling 변수로 인해 발생한 NaN 값은 제거
2. Train-Test Split
8:2 비율로 Train 데이터 셋과 Test 데이터 셋을 나눠줍니다.
시계열 데이터이기에, 시간 변수 기준으로 분할해야합니다. (cross-validation 불가)
# index 번호 기준 8:2 split
split_idx = int(len(df) * 0.8)
train = df.iloc[:split_idx].copy()
test = df.iloc[split_idx:].copy()3. Encoding & Scaling
1) One-Hot Encoding
- 범주형 변수인
dayofweek와season등을 One-Hot Encoding하였습니다.
df = pd.get_dummies(df, columns=['dayofweek'], prefix='dow', drop_first=True)2) Standard Scaling
avg_temp_mean,esi_mean,marketplace_ratio등 주요 수치형 변수들은StandardScaler를 사용하여 스케일합니다.
train 데이터셋에 fit하고 train/test 데이터셋 모두에 transform을 적용합니다.
from sklearn.preprocessing import StandardScaler
num_cols = df.select_dtype(include=np.number).columns
scaler = StandardScaler()
train[num_cols] = scaler.fit_transform(train[num_cols])
test[num_cols] = scaler.transform(test[num_cols])III. ARIMA
본격적인 모델링을 시작합니다.
ARIMA 모델을 사용하여 타겟변수 ‘revenue_sum’을 예측합니다.
ARIMA 모델에 대한 이론적 내용은 ARIMA 모형 이해하기를 참고하세요
1. 차분하기
타겟변수 ‘revenue_sum’(일일 매출 합계)로 Line chart를 그려봅니다.
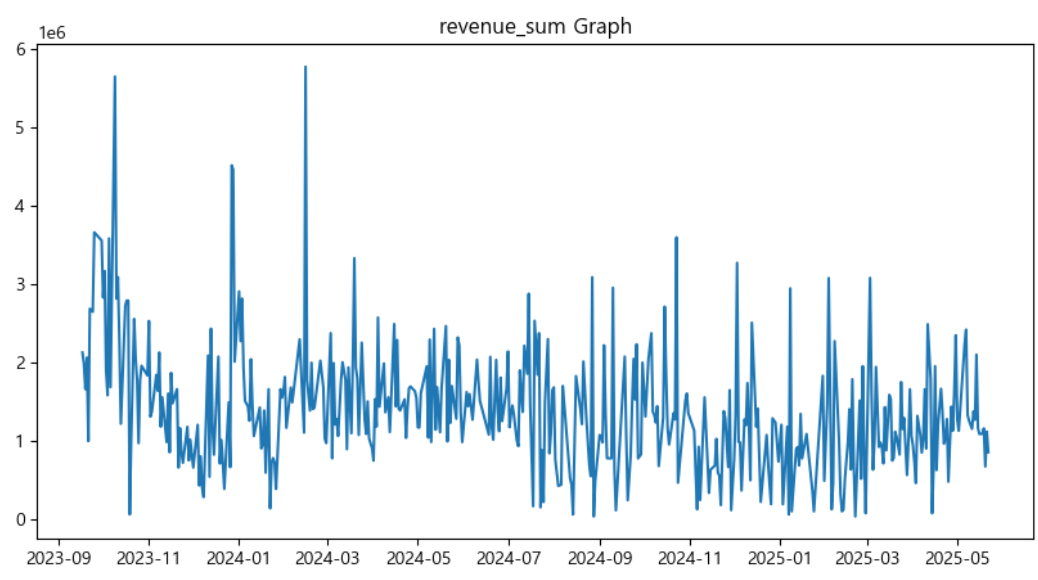
??? 매출액이라 그런지 어느 정도 정상성을 띄는 모습입니다.
그래도 더 깔끔한 상태를 위해 차분을 진행합니다.
diff_1 = df_train['revenue_sum'].diff().dropna()
diff_2 = diff_1.diff()
plt.subplot(2,1,1)
plt.plot(diff_1)
plt.title('d=1')
plt.subplot(2,1,2)
plt.title('d=2')
plt.plot(diff_2)
plt.show()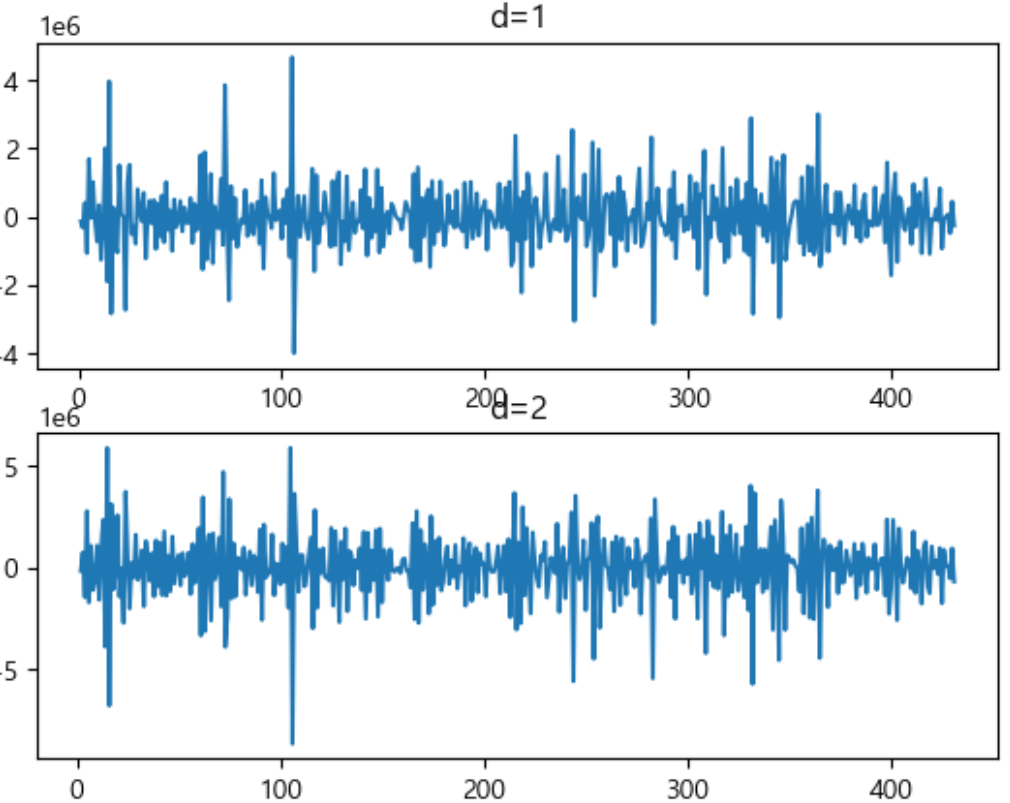
보아하니 1차 차분 시, 더욱 평균과 분산이 안정된 모습입니다.
이로서 ARIMA 모델의 차수 (p, d, q) 중 d는 1이 됩니다.
2. 차수 결정을 위한 자기상관도 및 추세성 확인
Autocorrelation과 Partial Autocorrelation을 확인합니다.
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
fig, ax = plt.subplots(2,1, figsize=(8,8))
plot_acf(df_train['revenue_sum'], lags=20, ax=ax[0])
plot_pacf(df_train['revenue_sum'], lags=20, ax=ax[1])
두 차트 모두 0번째(자기 자신) 이후의 상관계수가 뚝 떨어지는 경향을 띕니다.
그렇다고 바로 신뢰구간 안으로 들어오는 것은 아니기 때문에, MA차수 p와 AR차수 d는 0~2 값이 적절해보입니다.
itertools 라이브러리를 이용하여 간단하게 반복문을 돌려봅니다.
import itertools
p = range(0,3)
d = range(0,3)
q = range(0,3)
ls_pdq = list(itertools.product(p,d,q))
aic = []
for val_pdq in ls_pdq:
model = ARIMA(y_train, order=val_pdq)
model_fit = model.fit()
print(f'ARIMA: {val_pdq} >> AIC : {round(model_fit.aic, 2)}')
aic.append(round(model_fit.aic, 2))모델의 설명력과 복잡성을 동시에 고려하는 AIC 점수를 확인, ARIMA 모델의 최종 차수는 p, d, q = (2, 1, 2) 로 선정되었습니다.
3. ARIMA 모델링 결과
model을 fit한 뒤 결과를 확인해봅니다.
from statsmodels.tsa.arima.model import ARIMA
# 모델 학습/fit
model = ARIMA(y_train, order = (2,1,2), trend='n')
model_fit = model.fit()
# forecast
forecast_steps = 30
forecast = model_fit.forecast(steps=forecast_steps)
# visualization
plt.figure(figsize=(10,6))
plt.plot(y_train, label='Actual Data')
plt.plot(np.arange(len(y_train), len(y_train) + forecast_steps),
forecast, label="Forecast", color='red')
plt.legend()
plt.show()1) Forecast 30 step 결과

결과가 처참합니다… 그냥 평균치로 예측해버리는 모습이네요. Underfitting이 예상됩니다.
모델의 주요 평가 지표를 확인해보면
- RMSE: 723696.82 (실제 값 평균이 100만 원 정도 입니다;)
- R2: -0.06 (무슨?? 마이너스가 나와버리네요..)
- AIC: 10343.75 (앞서 진행한 차수 결정을 위한 반복문에서 AIC가 가장 낮은 값을 선정했지만, 그마저도 1만이 넘었습니다..)
2) 망한 이유는 무엇일까요?
결론부터 말씀드리자면, 해당 데이터셋이 ARIMA 모델에 적합하지 않은 것이 가장 큰 원인으로 파악됩니다.
ARIMA는 자기상관성과 추세를 통해 미래를 예측하는 모델이기에, 과거 매출과 오늘의 매출 간 상관도가 낮고, 추세도 또한 낮은 매출액 데이터는 잘 예측해내지 못하는 것이죠.