Overview
2025년 2학기 캡스톤디자인 과정에서 Design Thinkg을 통한 과제 정의와 Sales 데이터로 진행한 EDA 과정을 설명합니다.
데이터 전처리, Kakaomap-api 활용, Folium Gis 분석, 상관관계 분석 방법과 코드를 확인할 수 있습니다.
Platform: Python
First upload date: 2025-12-18
I. 들어가며
2025년 2학기, 융합캡스톤디자인1 대학 수업에서 데이터 분석 팀 프로젝트를 진행하였습니다.
저희는 신발 판매 회사의 매출 데이터를 토대로 경영 불확실성 해소를 위한 대시보드 제작이란 과제를 정의하였고, 여러 KPI를 수립한 뒤 Tableau를 이용하여 대시보드를 개발하였습니다.
Design Thinking → 데이터 전처리 및 EDA → 모델링 → Tableau 대시보드 개발 → 최종 발표 순으로 진행된 과정을 설명드리겠습니다.
1화에서는 EDA까지 진행됩니다.
II. 기획: Design Thinking
Design Thinking은 사용자의 숨겨진 니즈를 깊이 이해하고 문제를 재정의하는 데서 출발하는 창의적 문제 해결 방식이라고 합니다.
일반적으로 공감하기(Empathize) → 문제 정의(Define) → 아이디어 도출(Ideate) → 프로토타입(Prototype) → 테스트(Test) 순서대로 진행되는데 저희는 간단하게 아이디어 도출까지만 진행하였습니다.
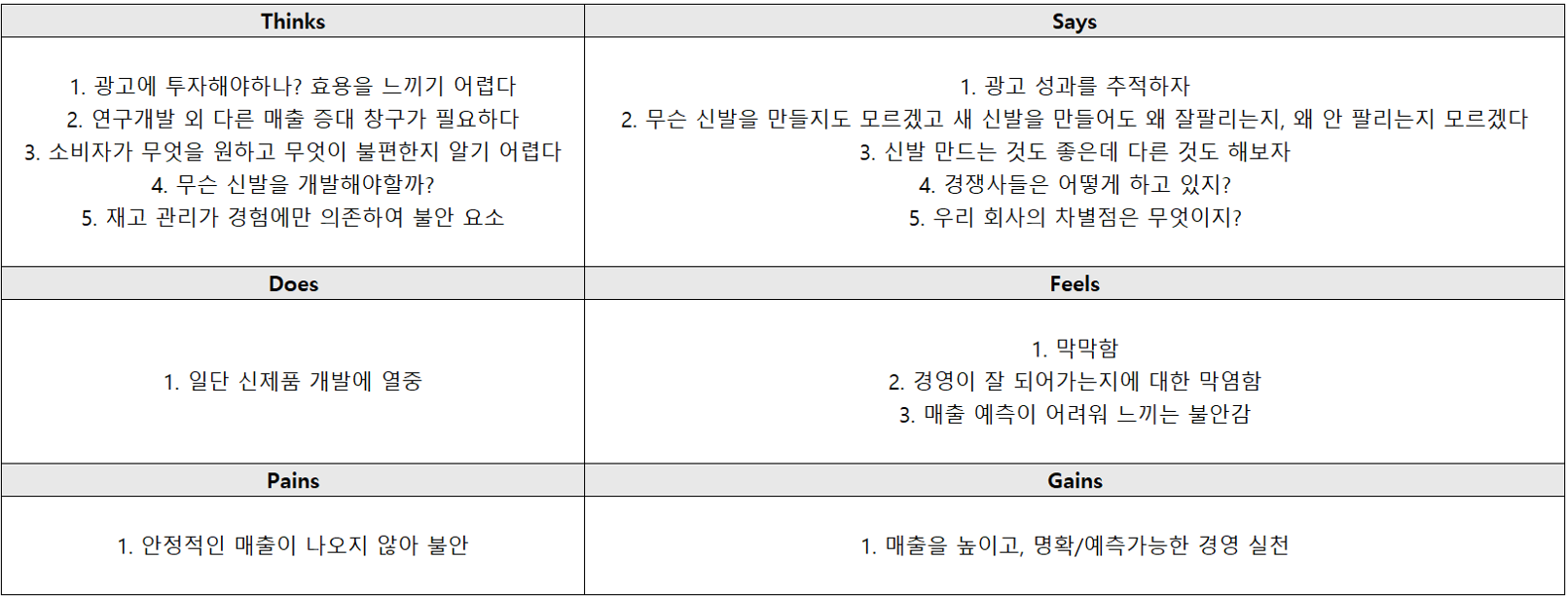
1. Empathize: 공감 지도
공감 지도는 원래 인터뷰, 관찰, 사용자 발언 등을 취합하여 작성해야 하지만, 편의상 저희의 상상력을 발휘하여 제작해보았습니다.
2. Define: 페르소나 정의서
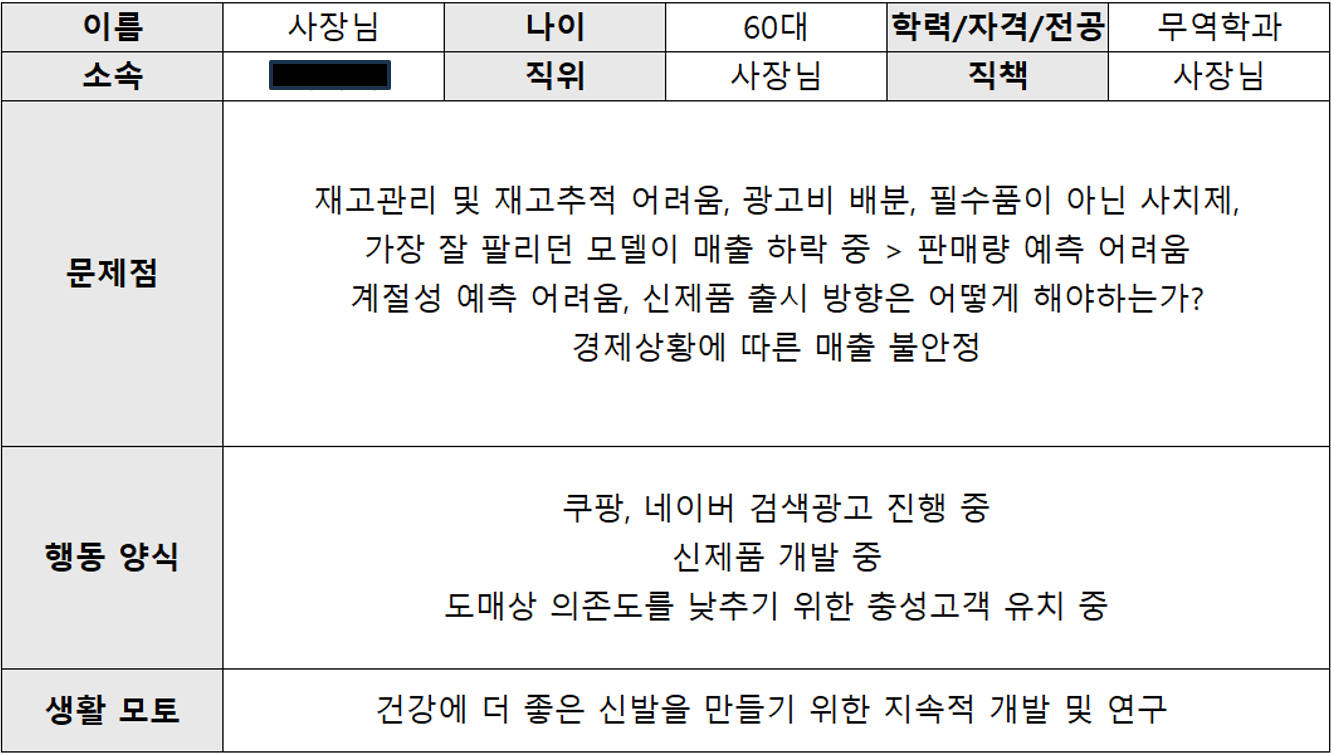
페르소나 정의서란 제품/서비스 등의 핵심 타겟 사용자를 실제처럼 구체화한 가상의 인물 프로필을 말합니다.
저희는 역시 상상력을 최대로 발휘하여 회사 사장님을 타겟 사용자로 설정하고, 아래와 같이 페르소나 정의서를 작성하였습니다.
3. Ideate: 브레인 스토밍
브레인 스토밍 등 팀원들과의 회의를 통해 여러 아이디어를 도출하였습니다.
최종적으로 월 매출액, 판매 채널 별 매출액, 제품 종류별 매출액 등을 KPI로 설정하여 대시보드를 구성키로 하였습니다.
III. 데이터 전처리 & EDA
1. Data Cleaning
정돈되지 않은 실제 기업의 데이터이다 보니 참으로 문제가 많았습니다.
 (24361 rows x 13 columns)
(24361 rows x 13 columns)
벌써부터 보이는 UNKNOWN과 이걸로 뭘 할 수 있을까 싶을 정도로 빈약한 변수들..
우선 UNKNOWN과 0원 처리된 값들을 전부 결측으로 처리하고, 기타 오기입된 행들을 수정하는 데이터 클리닝 작업을 진행하였습니다. (이 작업에 전체 작업 시간 중 50%정도 소요된 것 같습니다…)
2. 파생변수 생성
1) model, color
잘 보시면 ‘model_code’ 변수는 ’-‘을 사이에 두고 신발의 카테고리 코드 + 색상으로 이루어져 있습니다. split 매서드를 사용하여 ‘model’ 변수와 ‘color’ 변수로 나누어 주었습니다.
df['model'] = df['model_code'].apply(lambda x: x.split('-')[0])
df['color'] = df['model_code'].apply(lambda x: x.split('-')[1])2) gender
또한, 신발 사이즈 수치 정보가 담긴 ‘size_mm’ 변수를 250을 기준으로 남녀를 구분하였습니다.
df['gender'] = df['size_mm'].apply(lambda x: x >= 250) + 0 # 250 이상이면 13) region_1depth, lon/lat
‘address’ 변수에는 고객의 상세주소가 기입되어있습니다. 여기서 kakao map api를 이용하여 시/도 단위 지역명과 위/경도를 추출합니다.
import request
# kakao api 호출
url = "https://dapi.kakao.com/v2/local/search/address.json" #요청할 url 주소
Key = 'your_rest_api_key' #REST API 키(유효한 키)
headers = {"Authorization": f"KakaoAK {key}"}
# 사용자 정의 함수 생성
def udf_get_region1depth(addr):
try:
result = requests.get(url, headers=headers,
params = {'query': addr}).json()
region_1depth = result['documents'][0]['address']['region_1depth_name']
lon = result['documents'][0]['address']['x']
lat = result['documents'][0]['address']['y']
return region_1depth, lon, lat
except: # 예외처리
return np.nan
df[['region_1depth','lon','lat']] = df['address'].apply(udf_get_region1depth).apply(pd.Series)3. 외부변수 추가
기존 데이터 세트가 빈약하여 통계청과 기상청에서 외부변수 몇 개를 충당하였습니다.
- CPI : 소비자 물가 지수
- ESI : 경제 심리 지수
- temp : 일 평균 기온
- rain_num : 일 평균 강수량
4. 즐거운 EDA
주요 Insight 위주로 설명드리겠습니다.
1) GIS 분석
주문 지역을 folium 라이브러리로 지도 시각화 하였습니다.
import folium
m = folium.Map(location=[37.572, 126.985],
zoom_start=7,
tiles="cartodbpositron")
for idx, row in df.itterows():
try:
folium.Circle(location=[row['lon'], row['lat']],
fill=True, fill_opacity=1, color='red').add_to(m)
except:
continue결과
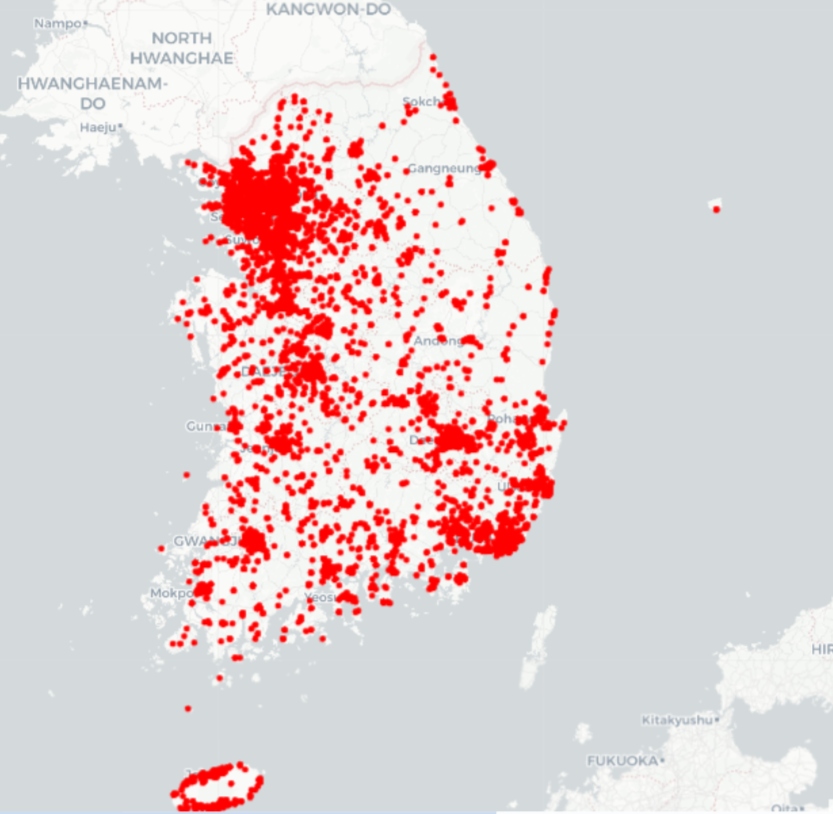
- Insights : 지역별 판매량 편차 확인
- 서울, 경기, 부산 등 인구 多 대도시에 주문이 집중되어 있습니다.
- 강원도, 경북 산간 지역은 눈에 띄게 주문이 적습니다.
2) 상관분석
수치형 변수 간 Correlation Matrix를 그려보았습니다.
sns.heatmap(df.corr(), cmap = 'coolwarm', # colormap 지정
annot = True, # 실제 값을 표시
linewidths=.5, # 경계면 실선으로 구분
cbar_kws={"shrink": .5},# 컬러바 크기 절반
vmin = -1,vmax = 1 # 컬러바 범위 -1 ~ 1
)결과 1
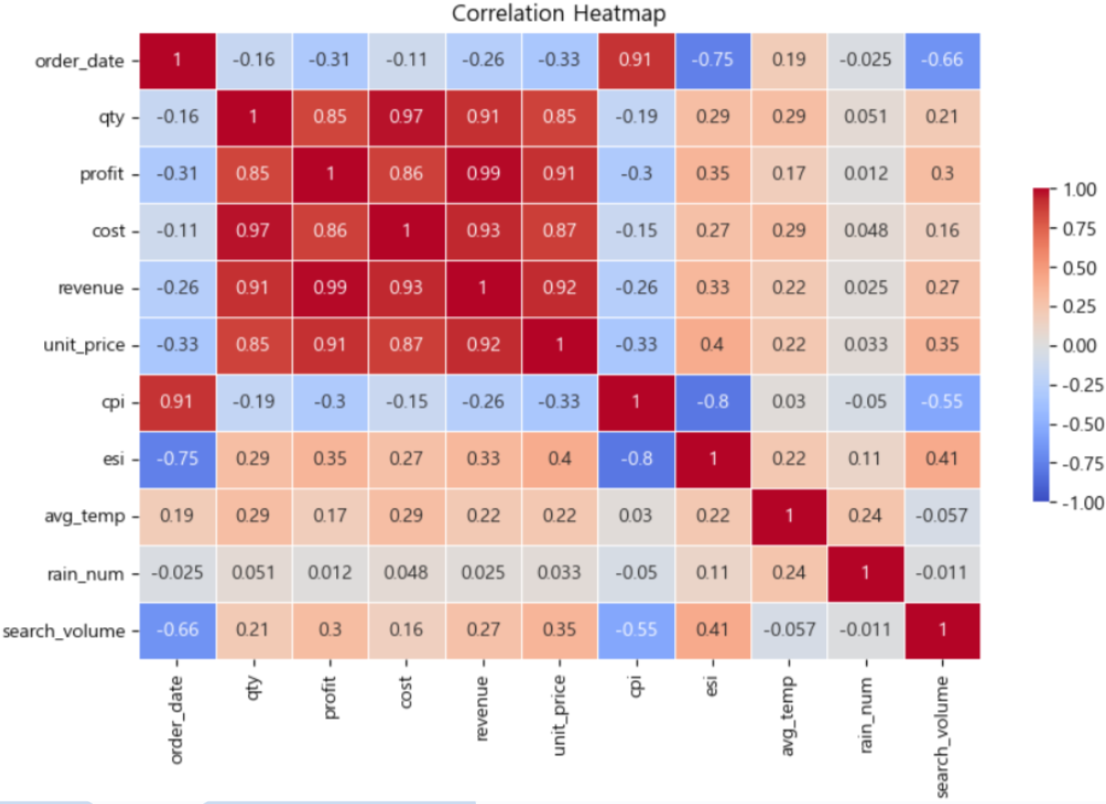
order_date와 외부변수 cpi, esi 간에 아주 강한 상관관계가 눈에 띕니다.
추후 모델링 시 다중공선성이 우려돼 vif 점수를 확인해보았습니다.
결과2
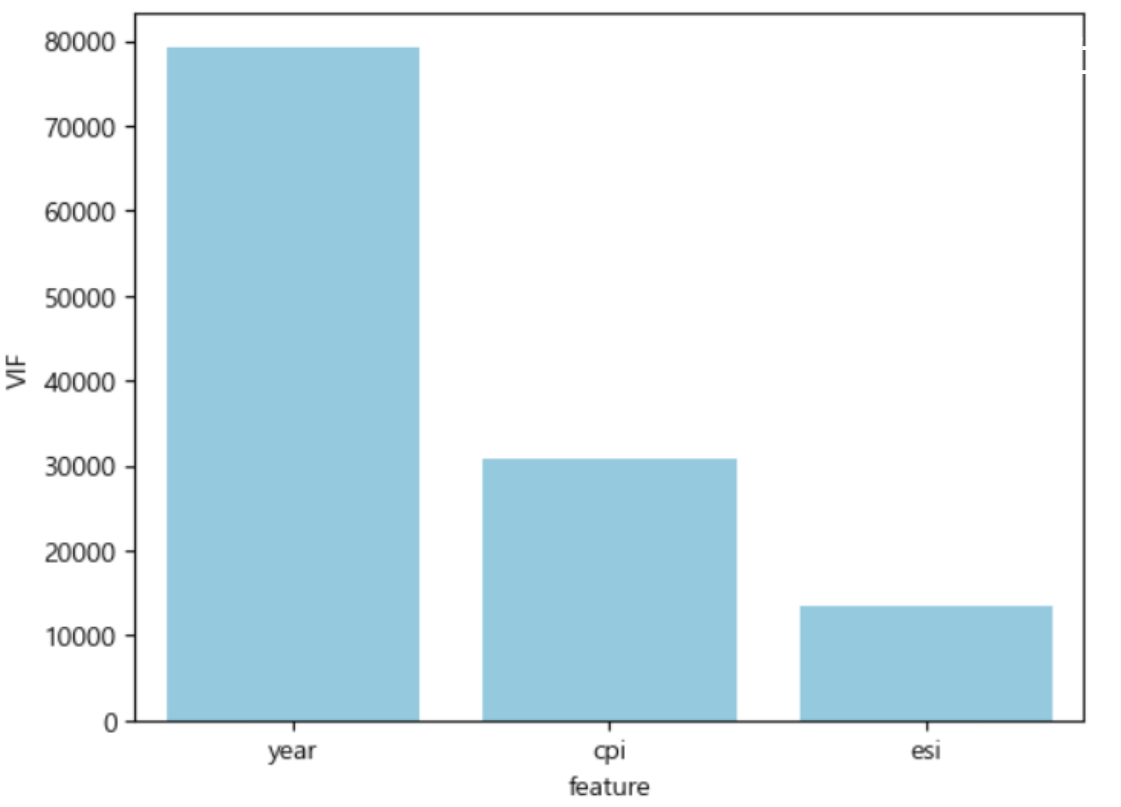
- Insights : 계절성 및 다중공선성 확인
- 매출(revenue)변수와 계절성(order_date, avg_temp 등) 변수 간 약한 상관관계가 있는 것으로 보아 매출에 Seasonal 요인이 작용한다는 사실을 파악할 수 있습니다.
- 심각한 다중공선성을 일으키는 변수를 제거해야 한다는 사실을 알았습니다.
IV. 나가며
프로젝트를 정리할수록 미숙한 점이 너무 많이 보여 아쉬움이 큽니다.
특히 데이터 클리닝 작업에서 노하우가 부족해 시간과 체력을 너무 많이 소모한 것에 비해서 클리닝 결과가 그리 좋지는 않았고, 이것이 부실한 EDA 결과를 낳은 것이 매우 아쉽습니다.
탄탄한 EDA의 중요성은 2편에서 보여드릴 모델링 과정에서 확인하실 수 있습니다.
관련 게시글 & 참고문헌
- 다음화 보러가기
- Python Data Analysis Cheat-Sheet
Footnotes
-
※ 캡스톤디자인: 실제 산업체/사회 문제를 발굴하고 기획, 설계, 제작, 평가하는 전 과정을 팀 프로젝트로 수행하는 종합 설계 교육 ↩